This is the written version of a talk I gave at the 2022 MIT Bitcoin Expo. You can watch the talk here, but honestly you should just read this post instead.

Hi everyone. I'm Luke Champine, and I'm a core developer at the Sia Foundation. Sia is a distributed cloud storage platform running on its own layer-1 blockchain. We've been around for a while; long enough that, back when we started, you didn't call it a "layer 1" blockchain. There was only one layer!
Anyway, Sia is fairly conservative as blockchains go. We tend to follow the Bitcoin approach towards writing consensus code, which is: don't. We wrote all our consensus code in the first year, tested the hell out of it, launched our mainnet, and didn't touch it again for a long time. But like any good project, we kept an eye on the new ideas circulating within the crypto space. And one of the developments that really caught our attention was Utreexo.

As it so happens, Tadge Dryja gave the first public talk on Utreexo right here, at the 2019 MIT Bitcoin Expo. We were watching that talk, and it got us pretty excited — so excited that we decided to overhaul our battle-tested consensus code and make Sia the world's first Utreexo-native blockchain.
Utreexo brings a lot of neat benefits to end-users, like faster syncing. But one of its most important effects is that it makes it vastly easier to join the network as a full node. Running a fully-validating node today requires significant resources. But with Utreexo, we can have nodes that only take up a few kilobytes, and can go from a clean slate to validating new blocks in less than a second.
That's not what this talk is about, though. We already knew about that stuff; Tadge and his team have done a great job of getting the word out. What we didn't anticipate was how Utreexo would change the way we think about consensus code.

Here's a question that I think goes somewhat unexamined: In a network like Bitcoin, what are we actually seeking consensus on? In other words, what do all nodes on the network have in common? I don't know if there's already an established name for this, but in this talk I'm going to call it the consensus surface.
We're talking about blockchains, so clearly we're seeking consensus on blocks, right? Well, no. That can't be true, because pruned nodes exist. Pruned nodes don't store the entire blockchain, yet they can validate new blocks, so they're still considered full nodes. So I think this answer is wrong. Instead, I'm going to argue that the real answer to this question is a lot weirder. I think that we're seeking consensus on...

...functions.
Specifically, two functions. We'll take them one at a time, starting with the validation function.

This is the function that decides whether or not we should accept a block. The thing to recognize here is that validation always occurs within a particular context. We don't validate blocks in a vacuum; what we're asking is, "Should we accept block X as the next block of chain Y?" So: what information do we need in order to answer that question? What pieces of data comprise our validation context?
I've listed some of them here. Hopefully these are all pretty intuitive. For example, you need to know the current difficulty so that you can check whether the block has enough work; you need to know the median timestamp of the last 11 blocks, so that you can check whether the block is too far in the past, etc. Simple stuff.
I feel like something's missing, though...
Ah. Right. The UTXOs.
We need to verify that every output spent in a block is actually spendable. The simplest way to do that is to store every output in a "UTXO set." When an output is created, we add it to the set, and when an output is spent, we delete it. If a block tries to spend an output that doesn't exist, we'll notice that it's not present in our UTXO set, and reject the block.
Just one problem: this totally sucks.
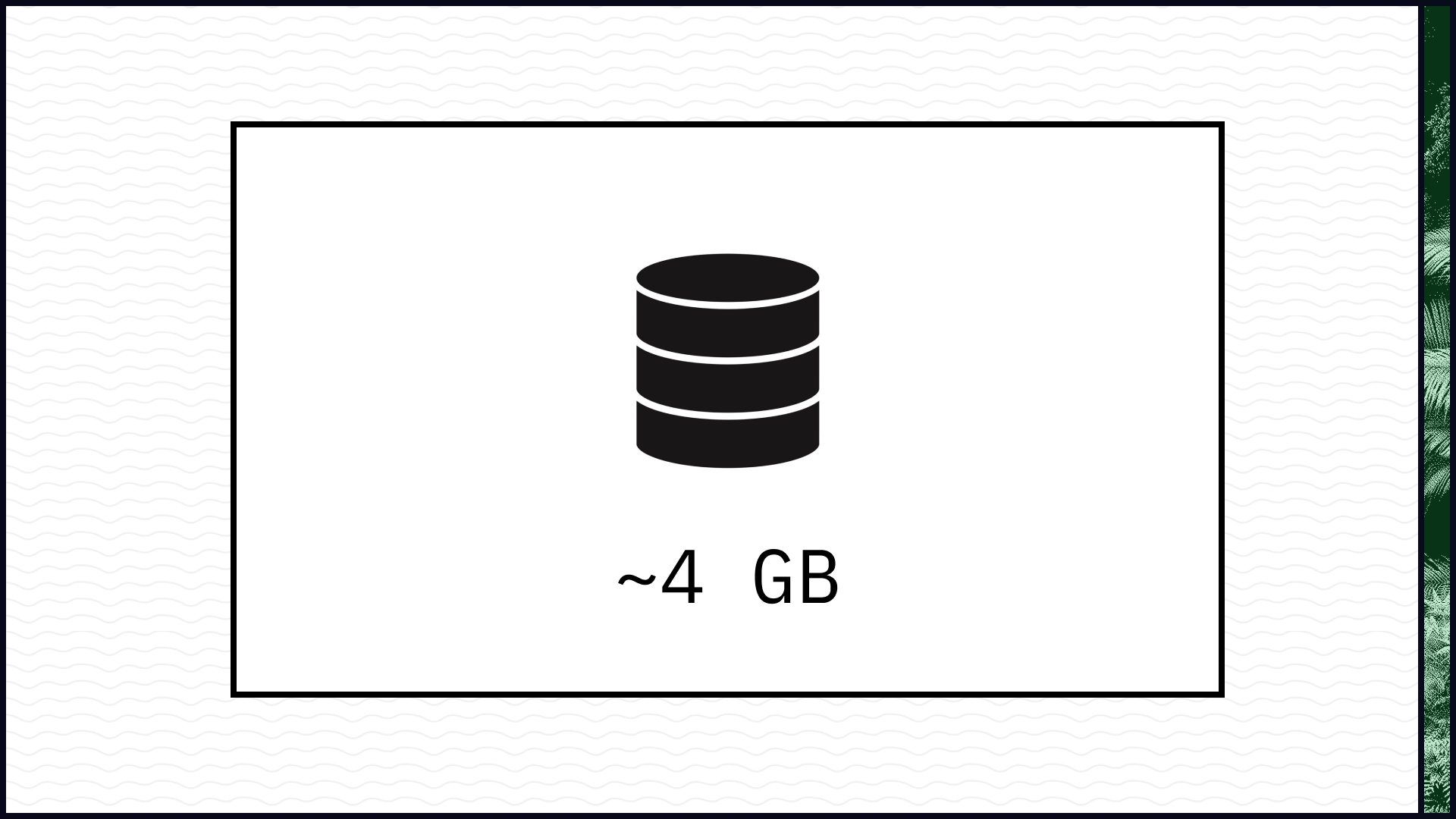
It sucks because there are millions of these UTXOs, so our set takes up quite a bit of space. Right now, it's around 4 GB. 4 GB isn't huge, but it's big enough that we can't just load the whole thing into memory. Moreover, we have to manage this set using a database. And databases are seriously complicated pieces of software. Bitcoin currently uses LevelDB as its database, which is about 20,000 lines of code, mostly written by people at Google who have nothing to do with Bitcoin.
So our validation context, which otherwise contains just a few tiny bits and bobs, has bloated to 4 GB. And our validation function, which was otherwise performing a handful of simple comparisons, now imports a giant esoteric blob of Google code. In other words, our consensus surface has absolutely exploded in size.
Okay, but why is this a problem? Isn't it cool that we can reach consensus on all this stuff? I mean, sort of, yeah. But the more stuff you have, the harder it is to maintain consensus. If any single UTXO among the millions we're storing gets corrupted or goes missing, we have a consensus failure. Plus, more code means more opportunities for bugs, not to mention backdoors. That's why I call it consensus surface: it's like attack surface. It's something you want to minimize. And this is where Utreexo comes in.
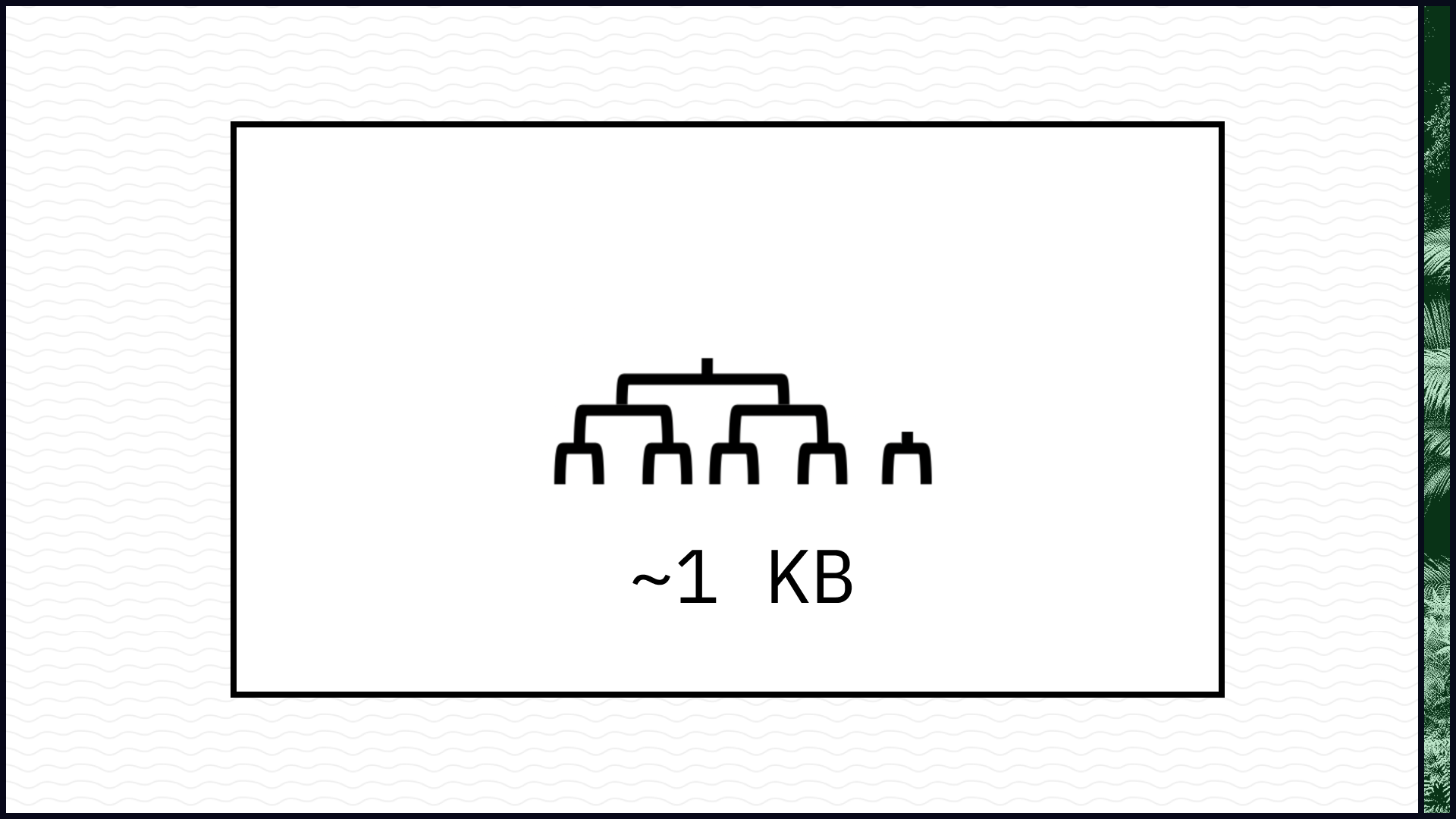
Utreexo replaces this giant, unwieldy UTXO database with a tiny cryptographic accumulator. The accumulator provides the same functionality as a database: you can add new elements to it, you can ask whether an element is present or not, and you can delete elements. The difference is that instead of storing the UTXOs themselves, the accumulator only stores a description of them. So we're still reaching consensus on the UTXOs, just in an indirect way.
The Utreexo accumulator is a type of Merkle tree, or rather a set of Merkle trees; Tadge calls it a "Merkle forest." The magical part is that you only need to store the root of each tree. So in code, your accumulator type is nothing more than an array of hashes, paired with a single integer (the number of leaves). Coincidentally, we had already been using this exact data structure in Sia for years — it's the basis for our storage proofs. I'm pretty enamored with it, honestly. (I wrote a whole paper on it!)
There are other kinds of cryptographic accumulator, but they have unfavorable tradeoffs and/or use very fancy math. A Merkle forest, on the other hand, is something that any blockchain core dev should feel comfortable with. The algorithms aren't trivial, per se, but they're vastly simpler than the hoops LevelDB has to jump through in order to present a uniform API across a whole matrix of CPU/OS/filesystem combinations.

At this point, you might be wondering: if we can replace that big database with a description of its contents, then why do we need this fancy accumulator thing? Why not just pipe all the UTXOs through SHA-256d? That way, we can shrink the whole set down to a single hash.
I mean, we could do that. But consider what happens when our UTXO set changes. We'd have to rehash the whole thing! Our Merkle forest can do much better: we can update it using good old-fashioned Merkle proofs, which are log(n) in the number of UTXOs.
This notion of "updating" the accumulator brings us to the other half of our consensus surface: the transition function. Validation is great and all, but once you've validated a block, you want to actually... do things with it. Things like updating the block height, the difficulty, the median timestamp — and of course, the UTXO set. In short, you want to prepare to validate the next block. That's what our transition function will do.
This is a generic transition function. We have some state, we apply an event to that state, and that produces a new state, along with zero or more effects. (If you're familiar with Urbit, this might sound familiar: it's the basis of their purely functional operating system.)
Imagine you're editing a document. You press a key — that's an event. The document changes — that's the new state. And finally, your screen refreshes to display the new document — that's an effect.
Functional programmers believe that this is the best way to model every system. They are wrong, but I will grant that this is an excellent way to model a blockchain. Our events are blocks, and our state is the consensus surface. And the transition function is pure — everything involved here is immutable, as a blockchain should be.
So if you're a functional programmer at a SF house party, and some weirdo is yelling in your ear about "block chain", you're probably picturing something like this diagram. You're thinking: "Finally! A project that brings together my starry-eyed zealotry for functional programming and libertarianism!"
Then you went home, downloaded the Bitcoin source code, and saw...
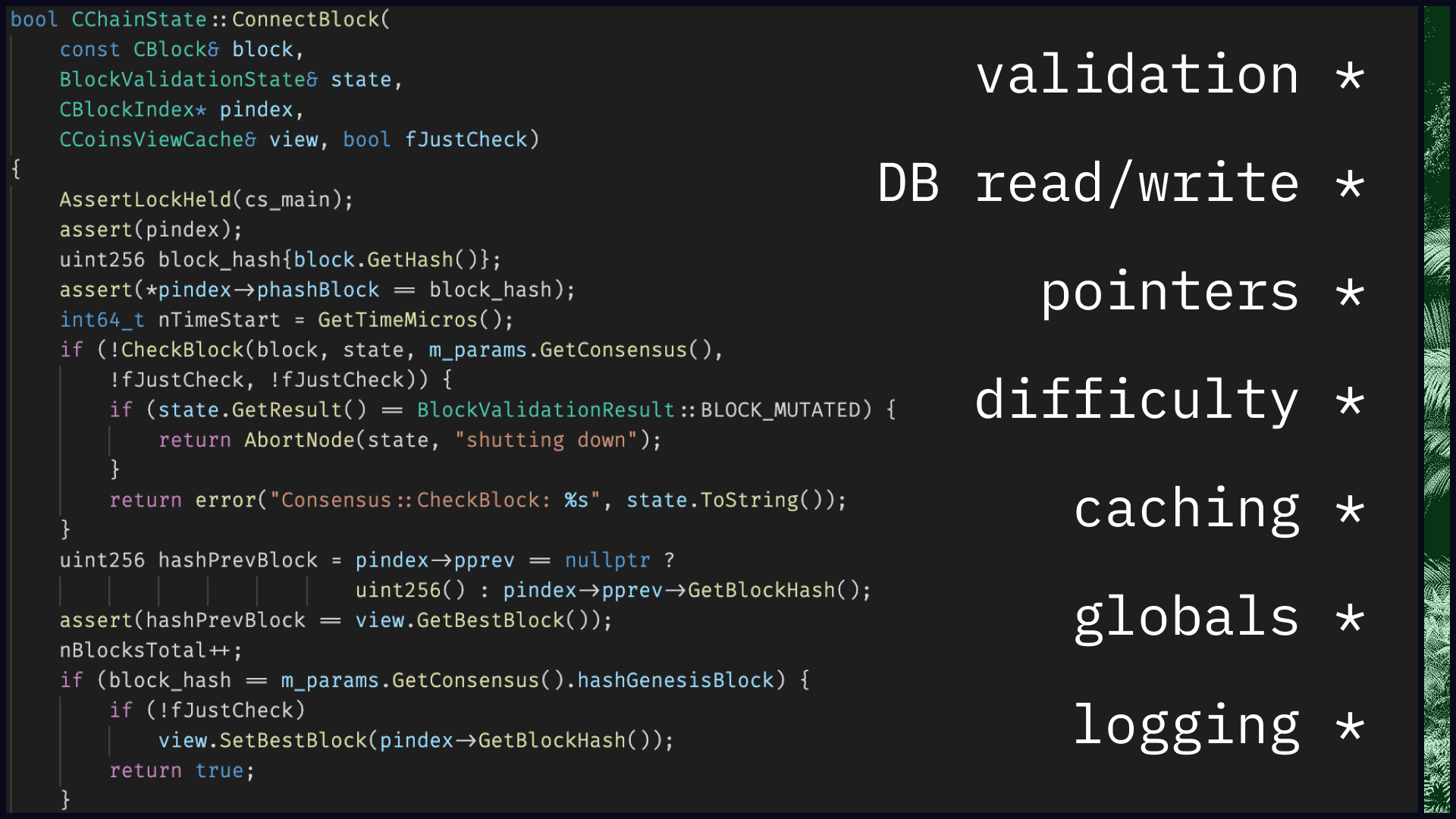
...this.
This is the Bitcoin core transition function, and it ain't pretty. For starters, it's not just the transition function: it's the validation function too. On top of that, this function performs just about every side effect imaginable. It reads and writes to disk. It mutates global variables. It outputs various logging statements. When I revisit this function now, though, what I find most offensive is how poorly-defined its boundaries are. What is this function doing? It's easy enough to answer that question at a high level: "It's validating the block, writing it to disk, and updating the UTXO set." But if I'm trying to truly understand the system, that isn't good enough. Which values are being accessed, and when? Which values are being modified, and when? These are the questions I want answers to, and there's no easy way to answer them except to crawl through the code, line by line.
To be clear, I'm not ragging on the Bitcoin core devs here. If you look at the Sia codebase, you'll see all the same stuff: database I/O, logging, global variables, it's all there. In short, something is just wrong with this picture: if functional programming is such a good fit for blockchains, why doesn't our code reflect that?
It all comes back to the UTXO set. There are lots of UTXOs, so we store them in a database. The database lives on disk, so we have to perform I/O to access it. The database is large, so we only maintain one copy, and mutate it in place. Since we're mutating in place, we have to ensure that we always transition immediately after validating, so we merge those two functions together. And now, because our function is slow, complicated, and can fail in many different ways, we throw in a bunch of logging statements.
The sad truth is that when your consensus code involves a database, this situation is essentially unavoidable. Bitcoin can't avoid it, Ethereum can't avoid it, Sia can't avoid it. And when this database is such a core part of your code, you stop modeling the blockchain as this nice sequence of immutable states, and start modeling it as a big mutable singleton.
But it doesn't have to be that way.
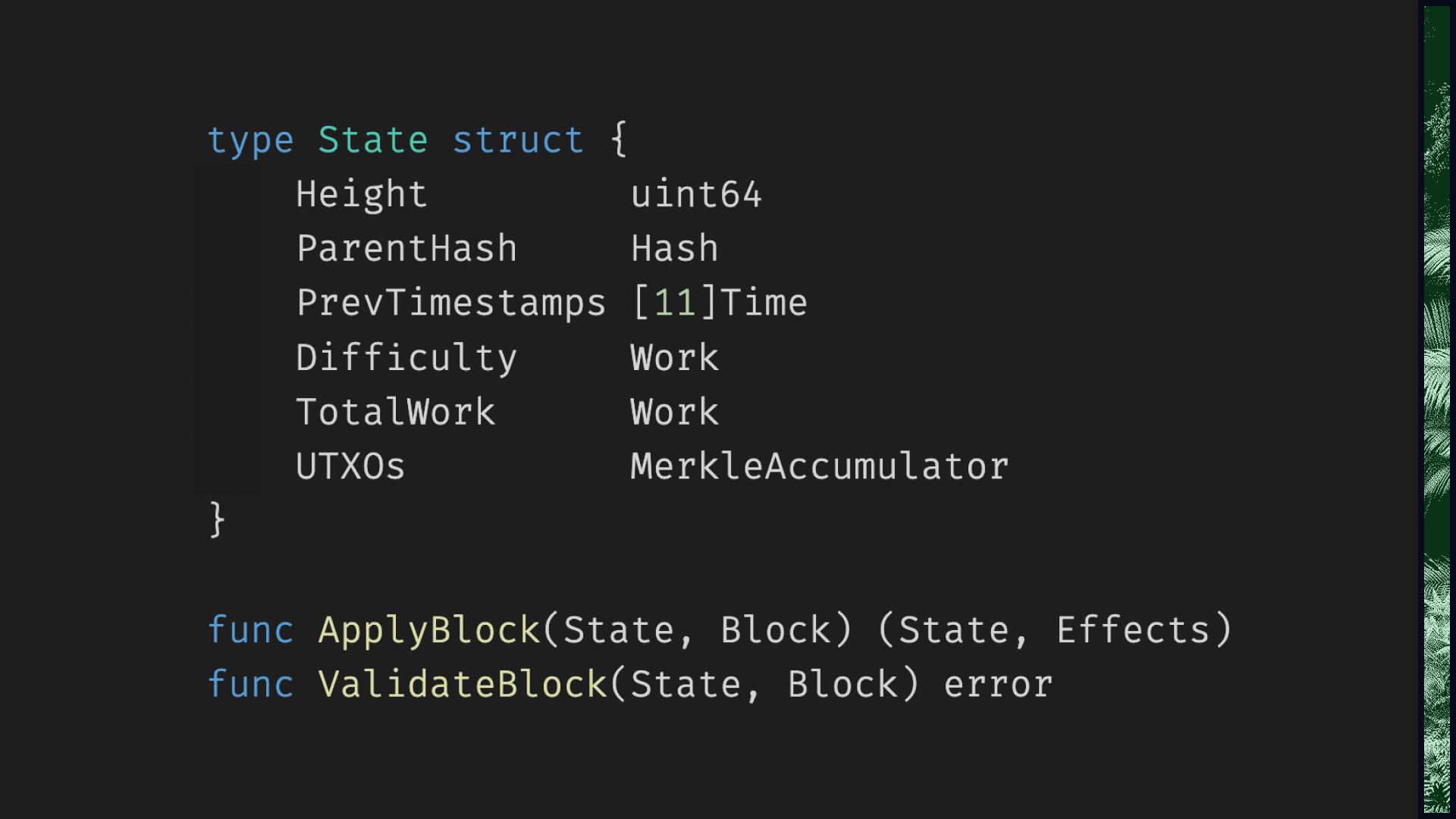
This is the new Sia. Thanks to Utreexo, our entire consensus state now fits in this struct. There are no pointers or file handles here; it's just a 1KB slab of inert data.
What data is the Sia network seeking consensus on? The bytes that make up this struct. No more, no less.
What data do we need in order to validate a block? The bytes that make up this struct. No more, no less.
Since this struct is small, it's cheap to copy. Which means our transition function can be pure: it can return a
new State object instead of mutating an existing one. And if our transition function is pure, we
might as well make our validation function pure as well.
A few milliseconds after I finished defining Sia's consensus surface in terms of these two pure
functions, I caught an acute case of Programmer Maximalism Syndrome. I thought: why not go all the
way? Why not define all of our consensus code relative to this State type? What
would that look like?
I started thinking about consensus rules, like the maximum block weight and the block reward. At the time, I had
a MaxBlockWeight constant, and a BlockReward helper function, and a few similar
pieces of code, all living in the same namespace as the validation and transition functions. In light of the new
State type, this struck me as cheating.
See, consensus surface is inherently relative, not absolute. The rules that we use to validate and
apply a block depend on the current State. But by defining a global MaxBlockWeight
value, we're implying that it will always be the same, regardless of circumstances! This becomes concerning when
you realize that these values will be referenced outside of consensus code as well. For example, when miners are
assembling a block, they'll compare against MaxBlockWeight to ensure that they don't add too many
transactions. But what happens if we decide to change that value? Any existing code that uses the old value will
be silently broken.

State-Maximalism offers a better approach. Rather than defining a global
MaxBlockWeight constant, we define a MaxBlockWeight method on our
State type. Effectively, this means we have made it impossible to ask, "What is the
maximum block weight?" Instead, we can only ask, "What is the maximum block weight as of state
X?" There's a very sensible symmetry here, because we ask this question "of" the state that we intend
to apply our transition function to. In other words, what we're really asking is, "Hey, state X, if I wanted to
apply a block to you, what's the heaviest block you would accept?"
If you're familiar with capabilities in
programming, that's pretty much what we're doing here. It's a form of
defensive programming:
by forcing the programmer to shuttle these State objects around, we prevent them from accidentally
painting themselves into a corner. This is a lesson we learned the hard way in Sia, by the way. We had a
SigHash method on our transaction type, which returned the hash used when signing or verifying a
transaction. But this method was totally context-free: it had no knowledge of the current state of the chain.
A few years later, it had come time to implement our first hardfork, and we realized that we needed to prevent
replay attacks, in which a signature on one chain
is reused on a different chain. In order to do that, we had to change our signature hashes... which meant that
we had to make SigHash behave differently based on which fork it was on. Our solution was to pass
the current block height to SigHash, and as a result, we had to run around our codebase updating
every callsite, and updating the callers of those callsites, and so on, plumbing these height values up
and down the stack. It was a huge pain, and it broke other people's code too, not just our own. If we had used a
capability-oriented design from the beginning, this situation would have been impossible by construction,
averting much wailing and gnashing of teeth.
Anyway. This is all very nice, but strictly speaking, it doesn't actually have anything to do with Utreexo. I mention it largely because this is a concept that you can apply to your consensus code, right now, even if you're not sold on this whole Utreexo thing. On that note, let's get back to me selling you on this whole Utreexo thing. Because now, we're ready to talk about its most important practical ramification, something I consider to be one of the holy grails of consensus code: isolation.

Because we've defined our consensus surface as pure functions, we can hermetically seal it off from the rest of the system. Any core dev will agree that this it highly desirable, for a number of reasons. For instance, it simplifies access control: you know exactly what code is "consensus code" and what isn't, so you can be very strict about who is allowed to change which lines of code. In the same vein, if you solicit a professional security audit, you can laser-focus that audit on just your consensus code. Isolation also simplifies testing; in particular, pure functions that operate on plain-old-data are perfect targets for fuzzing and formal methods.
More radically, you can treat your consensus code as an entirely separate compilation unit. There was actually an initiative to do this for Bitcoin some years ago, but AFAIK that effort has kinda stalled out. Partly because the Bitcoin source code wasn't originally architected that way — everything was mashed together and touching everything else — so there's a lot of inertia to fight. But also because the involvement of a big mutable database fundamentally restricts your ability to isolate things. Utreexo to the rescue: no database, no problem.
And once you're compiling consensus code separately, you might wonder: why stick with one language? You can write your consensus code in Rust, or Zig, or formally-verified C, and use a friendlier language for the rest. Alternatively, if you really want to lean into the FP angle, you can implement your consensus code in Lisp or Haskell or Idris or some crazy research language, and expose it as a microservice!
After crossing the file boundary, the language boundary, and the network boundary, there's only one more boundary left: the hardware boundary. Just as a hardware wallet isolates your seed phrase from untrusted computers, a "hardware validator" could isolate your consensus code. In this model, you would download blocks on your laptop as usual, but you'd stream them to a USB dongle, which would validate them and compute the new state. At the end, you'd have a blockchain that's been fully validated by trusted hardware, along with a trusted final state that can be shared with other users. The whole process would be extremely fast, too, since the validator would essentially be an ASIC, with hardware-accelerated hashing and signature verification.

Now, there's a big asterisk attached to all this. The asterisk is that we're not going to able to realize most of these benefits in Bitcoin. In order to achieve the level of isolation I've described here, you need to fully commit to Utreexo, and that means a hardfork. Hardforking may be viable for a project like Sia, but the likelihood of anyone pushing through such a massive change to Bitcoin is vanishingly small. That's why Tadge and his team have taken their "bridge node" approach: it's a clever way of bringing Utreexo functionality to Bitcoin without any forks. Ultimately, though, bridge nodes add complexity to an already-complex system. If you want to radically simplify your system, you have to be prepared to make radical changes.
Still, I think there are some lessons here that are applicable to any blockchain project, old or new. What I
would recommend to everyone writing consensus code today is: take stock of your consensus surface. Where is your
validation function? Where is your transition function? What are their dependencies, and what are their side
effects? If you were to define a State type, what would it contain? These questions might be harder
to answer than you expect!
After you've nailed down your consensus surface, ask yourself: can you make it smaller? Can you replace a large piece of data with a hash, or a Merkle root, or an accumulator? Can you replace your sophisticated database with something simpler? Are there any side effects you can eliminate?
Lastly, can you make your consensus surface more explicit? In particular, I strongly recommend embracing "relativity" in consensus code, as I described earlier. Don't make false promises in the form of global constants or context-free functions.
Think about a newcomer discovering your project for the first time, poking around your repo, wondering: "How does this thing work?" When we look closely at this question, we see that it's really two fundamental questions: what is the state, and how does that state evolve over time? My experience with Sia has shown me that if we strive to answer these questions openly and explicitly, we can write consensus code that is easier to understand, easier to audit, and easier to maintain.
That's all I've got for you today — thanks everyone. :)
